Page 1 of 1
Reinforcement Learning
Posted: Tue Dec 19, 2017 5:02 am
by Antonio Linares
Reinforcement Learning - A Simple Python Example and A Step Closer to AI with Assisted Q-Learning
Supervised and unsupervised approaches require data to model, not reinforcement learning! That’s right, it can explore space with a handful of instructions, analyze its surroundings one step at a time, and build data as it goes along for modeling
https://youtu.be/nSxaG_Kjw_w
https://amunategui.github.io/reinforcem ... index.html
Re: Reinforcement Learning
Posted: Tue Dec 19, 2017 5:32 pm
by Antonio Linares
https://www.oreilly.com/ideas/reinforce ... -explained
Reinforcement learning, in a simplistic definition, is learning best actions based on reward or punishment.
There are three basic concepts in reinforcement learning: state, action, and reward.
The state describes the current situation. For a robot that is learning to walk, the state is the position of its two legs. For a Go program, the state is the positions of all the pieces on the board.
Action is what an agent can do in each state. Given the state, or positions of its two legs, a robot can take steps within a certain distance. There are typically finite (or a fixed range of) actions an agent can take. For example, a robot stride can only be, say, 0.01 meter to 1 meter. The Go program can only put down its piece in one of 19 x 19 (that is 361) positions.
When a robot takes an action in a state, it receives a reward. Here the term “reward” is an abstract concept that describes feedback from the environment. A reward can be positive or negative. When the reward is positive, it is corresponding to our normal meaning of reward. When the reward is negative, it is corresponding to what we usually call “punishment.”
Re: Reinforcement Learning
Posted: Wed Dec 20, 2017 11:51 am
by Antonio Linares
Reinforcement learning is good for situations where information about the world is very limited: there is no given map of the world. We have to learn our actions by interacting with the environment: trial and error is required
Re: Reinforcement Learning
Posted: Fri Dec 22, 2017 7:09 pm
by Antonio Linares
http://mnemstudio.org/path-finding-q-le ... torial.htm
The transition rule of Q learning is a very simple formula:
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
The Gamma parameter has a range of 0 to 1 (0 <= Gamma > 1). If Gamma is closer to zero, the agent will tend to consider only immediate rewards. If Gamma is closer to one, the agent will consider future rewards with greater weight, willing to delay the reward.
In this case, if the matrix Q has been enhanced, instead of exploring around, and going back and forth to the same rooms, the agent will find the fastest route to the goal state.
Re: Reinforcement Learning
Posted: Fri Dec 22, 2017 7:25 pm
by Antonio Linares
Reinforcement Learning example (Q-Learning)
work in progress
qlearning.prg
Code: Select all
// AI: Reinforcement Learning example (Q-Learning)
// Harbour implementation by Antonio Linares
#include "FiveWin.ch"
function Main()
local aStates := { 0, 1, 2, 3, 4, 5 }
local aR := Array( Len( aStates ), Len( aStates ) ) // Rewards matrix
local aQ := Array( Len( aStates ), Len( aStates ) ) // Q-Learning matrix
local nGamma := 0.8
local nState := aStates[ hb_RandomInt( 1, Len( aStates ) ) ]
local nGoal := ATail( aStates )
local nAction
? "initial state:", nState
AEval( aR, { | aRow, n | aR[ n ] := AFill( aRow, -1 ) } ) // Initialize the Rewards matrix
AEval( aQ, { | aRow, n | aQ[ n ] := AFill( aRow, 0 ) } ) // Initialize the Q-Learning matrix
aR[ 1 ][ 5 ] = 0 // state 0 can only go to state 4
aR[ 2 ][ 4 ] = 0 // state 1 can only go to state 3 or
aR[ 2 ][ 6 ] = 100 // to state 5 (goal)
aR[ 3 ][ 4 ] = 0 // state 2 can only go to state 3
aR[ 4 ][ 2 ] = 0 // state 3 can only go to state 1 or
aR[ 4 ][ 3 ] = 0 // to state 2 or
aR[ 4 ][ 5 ] = 0 // to state 4
aR[ 5 ][ 1 ] = 0 // state 4 can only go to state 0 or
aR[ 5 ][ 4 ] = 0 // to state 3 or
aR[ 5 ][ 6 ] = 100 // to state 5 (goal)
aR[ 6 ][ 2 ] = 0 // state 5 can only go to state 1 or
aR[ 6 ][ 5 ] = 0 // to state 4 or
aR[ 6 ][ 6 ] = 100 // to itself (goal)
XBROWSER aR TITLE "Rewards matrix"
while nState != nGoal
nAction = NextAction( aR, nState )
? "next state", nAction
nState = nAction
end
return nil
function NextAction( aR, nState )
local aActions := {}
AEval( aR[ nState + 1 ],;
{ | nAction, nState | If( nAction == 0 .or. nAction == 100, AAdd( aActions, nState - 1 ), ) } )
XBROWSER aActions TITLE "Possible Actions for state: " + Str( nState )
return aActions[ hb_RandomInt( 1, Len( aActions ) ) ]
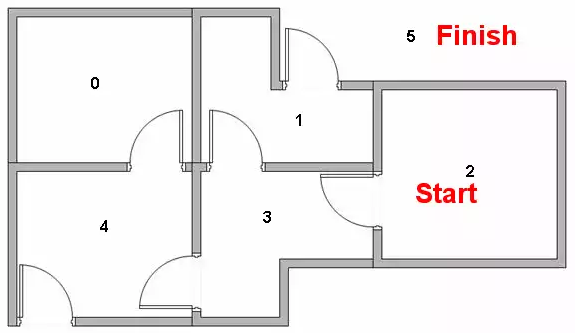
Re: Reinforcement Learning
Posted: Wed Dec 27, 2017 11:42 am
by Antonio Linares
With no learning. Just random tries...
qlearning.prg
Code: Select all
// AI: Reinforcement Learning example (Q-Learning)
// Harbour implementation by Antonio Linares
#include "FiveWin.ch"
function Main()
local aStates := { 0, 1, 2, 3, 4, 5 }
local aR := Array( Len( aStates ), Len( aStates ) ) // Rewards matrix
local aQ := Array( Len( aStates ), Len( aStates ) ) // Q-Learning matrix
local nGamma := 0.8
local nState := aStates[ hb_RandomInt( 1, Len( aStates ) ) ]
local nGoal := ATail( aStates )
local nAction
? "initial state:", nState
AEval( aR, { | aRow, n | aR[ n ] := AFill( aRow, -1 ) } ) // Initialize the Rewards matrix
AEval( aQ, { | aRow, n | aQ[ n ] := AFill( aRow, 0 ) } ) // Initialize the Q-Learning matrix
aR[ 1 ][ 5 ] = 0 // state 0 can only go to state 4
aR[ 2 ][ 4 ] = 0 // state 1 can only go to state 3 or
aR[ 2 ][ 6 ] = 100 // to state 5 (goal)
aR[ 3 ][ 4 ] = 0 // state 2 can only go to state 3
aR[ 4 ][ 2 ] = 0 // state 3 can only go to state 1 or
aR[ 4 ][ 3 ] = 0 // to state 2 or
aR[ 4 ][ 5 ] = 0 // to state 4
aR[ 5 ][ 1 ] = 0 // state 4 can only go to state 0 or
aR[ 5 ][ 4 ] = 0 // to state 3 or
aR[ 5 ][ 6 ] = 100 // to state 5 (goal)
aR[ 6 ][ 2 ] = 0 // state 5 can only go to state 1 or
aR[ 6 ][ 5 ] = 0 // to state 4 or
aR[ 6 ][ 6 ] = 100 // to itself (goal)
XBROWSER aR TITLE "Rewards matrix"
while nState != nGoal
nAction = NextAction( aR, nState )
? "next state", nAction
nState = nAction
end
return nil
function GetActions( aR, nState )
local aActions := {}
AEval( aR[ nState + 1 ],;
{ | nAction, nState | If( nAction > -1, AAdd( aActions, nState - 1 ), ) } )
return aActions
function NextAction( aR, nState )
local aActions := GetActions( aR, nState )
XBROWSER aActions TITLE "Possible Actions for state: " + Str( nState )
return aActions[ hb_RandomInt( 1, Len( aActions ) ) ]
Re: Reinforcement Learning
Posted: Wed Dec 27, 2017 12:34 pm
by Antonio Linares
Implementing the learning. Work in progress
qlearning.prg
Code: Select all
// AI: Reinforcement Learning example (Q-Learning)
// Harbour implementation by Antonio Linares
#include "FiveWin.ch"
function Main()
local aStates := { 0, 1, 2, 3, 4, 5 }
local aR := Array( Len( aStates ), Len( aStates ) ) // Rewards matrix
local aQ := Array( Len( aStates ), Len( aStates ) ) // Q-Learning matrix
local nGamma := 0.8
local nState := aStates[ hb_RandomInt( 1, Len( aStates ) ) ]
local nGoal := ATail( aStates )
local nAction
? "initial state:", nState
AEval( aR, { | aRow, n | aR[ n ] := AFill( aRow, -1 ) } ) // Initialize the Rewards matrix
AEval( aQ, { | aRow, n | aQ[ n ] := AFill( aRow, 0 ) } ) // Initialize the Q-Learning matrix
aR[ 1 ][ 5 ] = 0 // state 0 can only go to state 4
aR[ 2 ][ 4 ] = 0 // state 1 can only go to state 3 or
aR[ 2 ][ 6 ] = 100 // to state 5 (goal)
aR[ 3 ][ 4 ] = 0 // state 2 can only go to state 3
aR[ 4 ][ 2 ] = 0 // state 3 can only go to state 1 or
aR[ 4 ][ 3 ] = 0 // to state 2 or
aR[ 4 ][ 5 ] = 0 // to state 4
aR[ 5 ][ 1 ] = 0 // state 4 can only go to state 0 or
aR[ 5 ][ 4 ] = 0 // to state 3 or
aR[ 5 ][ 6 ] = 100 // to state 5 (goal)
aR[ 6 ][ 2 ] = 0 // state 5 can only go to state 1 or
aR[ 6 ][ 5 ] = 0 // to state 4 or
aR[ 6 ][ 6 ] = 100 // to itself (goal)
XBROWSER aQ TITLE "Q-Learning matrix"
while nState != nGoal
nAction = NextAction( aR, nState )
aQ[ nState + 1, nAction + 1 ] = aR[ nState + 1, nAction + 1 ] + nGamma * GetMaxQForActions( aQ, nState )
XBROWSER aQ TITLE "Q-Learning matrix"
? "next state", nAction
nState = nAction
end
return nil
function GetMaxQForActions( aQ, nState )
local nMax := 0
AEval( aQ[ nState + 1 ], { | nLearning | nMax := Max( nLearning, nMax ) } )
MsgInfo( nMax, "Max Q" )
return nMax
function GetActions( aR, nState )
local aActions := {}
AEval( aR[ nState + 1 ],;
{ | nReward, nState | If( nReward > -1, AAdd( aActions, nState - 1 ), ) } )
return aActions
function NextAction( aR, nState )
local aActions := GetActions( aR, nState )
XBROWSER aActions TITLE "Possible Actions for state: " + Str( nState )
return aActions[ hb_RandomInt( 1, Len( aActions ) ) ]